지난주에는 데이터의 종류와 Azure Managed Database를 살펴봤다.
이번 주는 실제로 데이터를 다루는 방법이다.
테이블, 인덱스, 뷰 같은 Database Object가 뭔지,
SQL로 어떻게 조작하는지,
그리고 Azure에서 제공하는 상용 SQL Server는 어떤 차이가 있는지
마지막으로 Python에서 MySQL에 직접 연결하는 아키텍처를 알아보자
4-1. 클라우드 데이터 조작 쿼리
Database Objects
관계형 데이터베이스에는 데이터를 효율적으로 관리하기 위한 여러 객체가 존재한다. 가장 기본이 되는 건 Table이고, 그 위에 Index, View, Relationship 같은 객체들이 얹어진다.
Table — 데이터가 실제로 저장되는 곳이다. 행(Row)과 열(Column)로 구성되고, 모든 행은 동일한 수의 열을 가진다. 각 열은 데이터 타입이 정의되어 있다. 고객 테이블이라면 CustomerID INT, CustomerName VARCHAR(100) 같은 식이다.
Entity — 테이블이 표현하는 대상이다. 고객, 제품처럼 실제 존재하는 항목일 수도 있고, 주문처럼 가상의 항목일 수도 있다. Entity 간의 관계가 곧 비즈니스 로직이 된다.
정규화(Normalization) — 데이터 중복을 제거하고 무결성을 보장하기 위해 테이블을 분리하는 과정이다. 정규화의 핵심 목적은 세 가지다: 스토리지 절감, 데이터 중복 방지, 데이터 품질 향상. 실무에서는 3NF(Third Normal Form)까지 적용하는 것이 일반적이다.
Relationship — 정규화된 테이블 간의 연결을 정의한다. Primary Key와 Foreign Key를 사용해서 관계를 표현하고, JOIN을 통해 분리된 데이터를 다시 합쳐서 조회한다. 예를 들어 고객 테이블의 CustomerID가 주문 테이블의 Foreign Key로 들어가면, 특정 고객의 주문 내역을 JOIN으로 가져올 수 있다.
Index — 검색 성능을 최적화하기 위한 객체다. 인덱스가 있으면 SQL 엔진이 전체 테이블을 스캔하지 않고, 인덱스를 통해 필요한 데이터 페이지만 읽는다. 다만 인덱스가 많을수록 INSERT/UPDATE 성능은 떨어지므로 트레이드오프를 고려해야 한다.
View — 쿼리 결과 집합을 기반으로 하는 가상 테이블이다. 복잡한 JOIN 쿼리를 매번 작성하는 대신, View로 한 번 정의해두면 단순한 SELECT로 동일한 결과를 얻을 수 있다.
-- View 생성
CREATE VIEW vw_customerorders AS
SELECT Customers.CustomerID, Customers.CustomerName, Orders.OrderID
FROM Customers
JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
-- View 사용
SELECT CustomerName, OrderID
FROM vw_customerorders
WHERE CustomerID = 102;SQL Query
SQL(Structured Query Language)은 관계형 데이터베이스의 표준 언어다. ANSI/ISO에서 표준을 관리하지만, 각 RDBMS는 자체 확장을 가지고 있다. SQL Server는 T-SQL, Oracle은 PL/SQL, PostgreSQL은 pgSQL이 대표적이다.
SQL문은 목적에 따라 세 가지로 분류된다.
| 분류 | 목적 | 대표 구문 |
|---|---|---|
| DML (Data Manipulation Language) | 데이터 조회/조작 | SELECT, INSERT, UPDATE, DELETE |
| DDL (Data Definition Language) | DB 구조 정의 | CREATE, ALTER, DROP, RENAME |
| DCL (Data Control Language) | 보안/권한 관리 | GRANT, REVOKE, DENY |
SELECT문의 구조:
SELECT EmployeeId, YEAR(OrderDate) AS OrderYear
FROM Sales.Orders
WHERE CustomerId = 71
GROUP BY EmployeeId, YEAR(OrderDate)
HAVING COUNT(*) > 1
ORDER BY EmployeeId, OrderYear;SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY 순서로 작성하지만, 실제 실행 순서는 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY다. 이 차이를 이해하고 있어야 복잡한 쿼리에서 오류를 피할 수 있다.
INSERT:
-- 단일 행 삽입
INSERT INTO Sales.OrderDetails (orderid, productid, unitprice, qty, discount)
VALUES (10255, 39, 18, 2, 0.05);
-- 멀티 행 삽입
INSERT INTO Sales.OrderDetails (orderid, productid, unitprice, qty, discount)
VALUES
(10256, 39, 18, 2, 0.05),
(10258, 39, 18, 5, 0.10);CREATE:
CREATE TABLE Mytable (
Mycolumn1 INT NOT NULL PRIMARY KEY,
Mycolumn2 VARCHAR(50) NOT NULL,
Mycolumn3 VARCHAR(10) NOT NULL
);4-2. 상용 클라우드의 데이터 플랫폼
IaaS vs PaaS
Azure에서 SQL Server를 운영하는 방식은 크게 IaaS와 PaaS로 나뉜다. 관리 부담과 제어 수준이 반비례한다.
| 구분 | 형태 | 관리 수준 | 제어 수준 |
|---|---|---|---|
| 온프레미스 SQL Server | 물리적 | 모든 것을 직접 관리 | 최대 |
| Azure VM의 SQL Server | IaaS | OS/패치/백업 직접 관리 | 높음 |
| Azure SQL Database | PaaS | 최소한의 관리 | 낮음 |
Azure에서 제공하는 3가지 SQL Services
Azure Virtual Machines의 SQL Server (IaaS) — 클라우드에서 SQL Server 정품을 그대로 돌린다. 온프레미스와 100% 호환되지만, OS 업그레이드, 패치, 백업, 복제 등 모든 관리를 직접 해야 한다. 요금은 데이터베이스 단위가 아니라 서버+라이선스 단위로 부과된다. 기존 온프레미스 SQL Server를 그대로 클라우드로 옮기려는 Lift & Shift 시나리오에 적합하다.
Azure SQL Database (PaaS) — 완전 관리형 데이터베이스 서비스다. 두 가지 배포 옵션이 있다.
| 옵션 | 특징 |
|---|---|
| 단일 데이터베이스 | 하이퍼스케일 스토리지(최대 100TB), 서버리스 컴퓨팅 지원 |
| 탄력적 풀 | 여러 데이터베이스가 메모리/스토리지/처리 능력을 공유. 비용 최적화에 유리 |
신규 클라우드 프로젝트에서 가장 많이 선택하는 옵션이다. 로드 변동이 있는 시스템에서 다운타임 없이 스케일 업/다운이 가능하다.
Azure SQL Managed Instance (PaaS) — SQL Database와 온프레미스 SQL Server의 중간 지점이다. 온프레미스 SQL Server와 거의 100% 호환되면서도 자동 백업, 패치, 모니터링 등 관리 작업은 Azure가 처리한다. 두 가지 배포 옵션이 있다.
| 옵션 | 특징 |
|---|---|
| 단일 인스턴스 | SQL Server의 대부분의 기능 노출, 기본 VNet 지원 |
| 인스턴스 풀 | 마이그레이션용 사전 프로비저닝, 작은 인스턴스(2vCore) 호스팅 가능 |
온프레미스에서 클라우드로 마이그레이션할 때, SQL Agent Job이나 Cross-database query 같은 인스턴스 레벨 기능이 필요하면 Managed Instance를 선택해야 한다. SQL Database는 이런 기능을 지원하지 않는다.
인증 및 액세스 제어
Azure SQL 서비스는 "혼합 모드" 인증을 강제한다. 배포 시 SQL 인증으로 서버 관리자를 생성한다.
Windows 인증이 필요한 경우에는 Azure AD Authentication을 지원하는 Managed Instance를 써야 한다. SQL Database에서도 Azure AD를 사용할 수 있지만, 포함된(Contained) 데이터베이스 사용자 방식이 권장된다.
Azure RBAC(역할 기반 액세스 제어)는 세 가지 요소로 구성된다: 보안 주체(Principal), 역할(Role), 범위(Scope). 이를 통해 누가, 어떤 리소스에, 어떤 작업을 할 수 있는지를 제어한다.
읽기 전용 복제본
읽기 복제본(Read Replica)은 주 서버에서 비동기로 데이터를 복제해서, BI/분석 같은 읽기 집약적 워크로드를 분리하는 데 쓰인다. 주 서버당 최대 5개까지 생성 가능하다. 재해 복구 시나리오에서는 다른 Azure region에 복제본을 두어 DR 용도로 활용할 수도 있다.
4-3. 데이터 플랫폼의 아키텍처 구성
MySQL Connector
Python에서 MySQL에 접속하려면 MySQL Connector 라이브러리를 사용한다. Oracle에서 공식 지원하는 라이브러리이고, 순수 Python으로 작성되어 별도 C 라이브러리 의존성이 없다. 다만 PyMySQL이나 mysqlclient에 비해 속도는 상대적으로 느리다.
pip install mysql-connector-python기본적인 사용 패턴:
import mysql.connector
cnx = mysql.connector.connect(
host="127.0.0.1",
port=3306,
user="root",
password="password",
database="database_name"
)
cursor = cnx.cursor()
cursor.execute("SELECT * FROM table_name")
results = cursor.fetchall()
cnx.close()전체 아키텍처는 사용자 ↔ Python(Streamlit 등) ↔ MySQL Connector ↔ MySQL DB 구조다. Connector가 Python 앱과 MySQL 사이의 브릿지 역할을 하고, 실제 데이터 조작은 SQL문을 그대로 사용한다.
실무에서는 mysql-connector-python 외에도 PyMySQL(순수 Python, 비동기 지원), mysqlclient(C 바인딩, 가장 빠름), SQLAlchemy(ORM) 등의 선택지가 있다. 단순 스크립트라면 MySQL Connector로 충분하고, 성능이 중요한 프로덕션에서는 mysqlclient를 추천한다.
실습 진행
SQL문 작성 실습을 진행해 보겠다.
먼저 MySQL 튜토리얼 사이트에서 샘플 쿼리문을 다운로드한 이후부터 진행한다.


이제 쿼리문을 직접 작성해보며 조회를 해보자
간단한 실습이라 쉽게 따라할 수 있었다.
이번에는 Azure SQL 리소스를 배포해보자
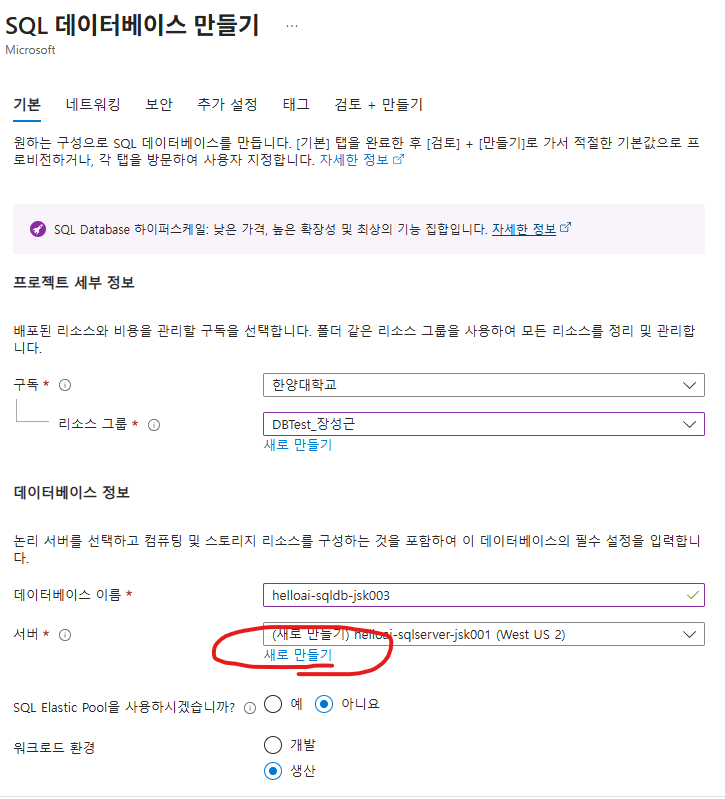
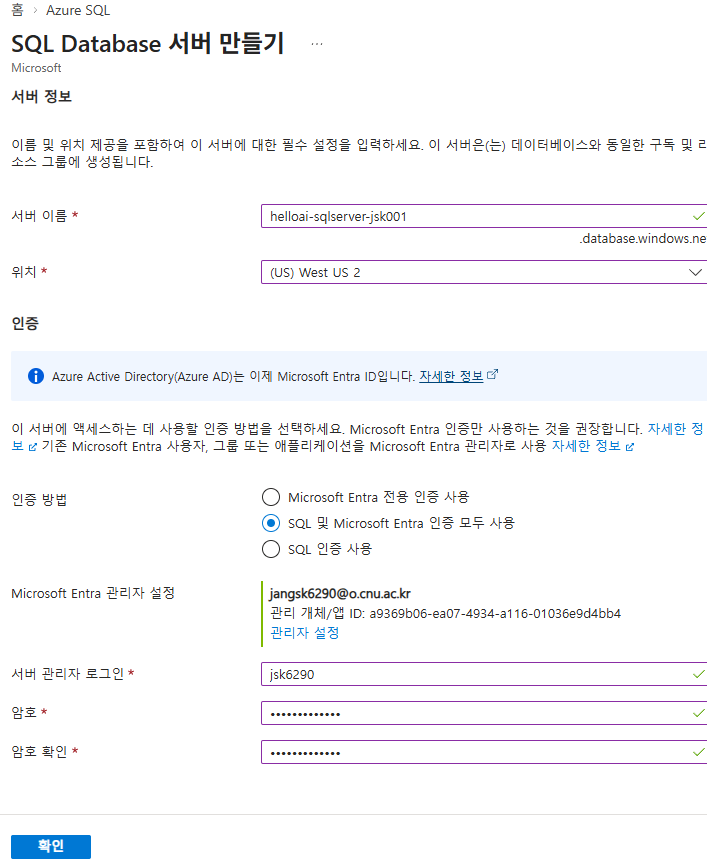

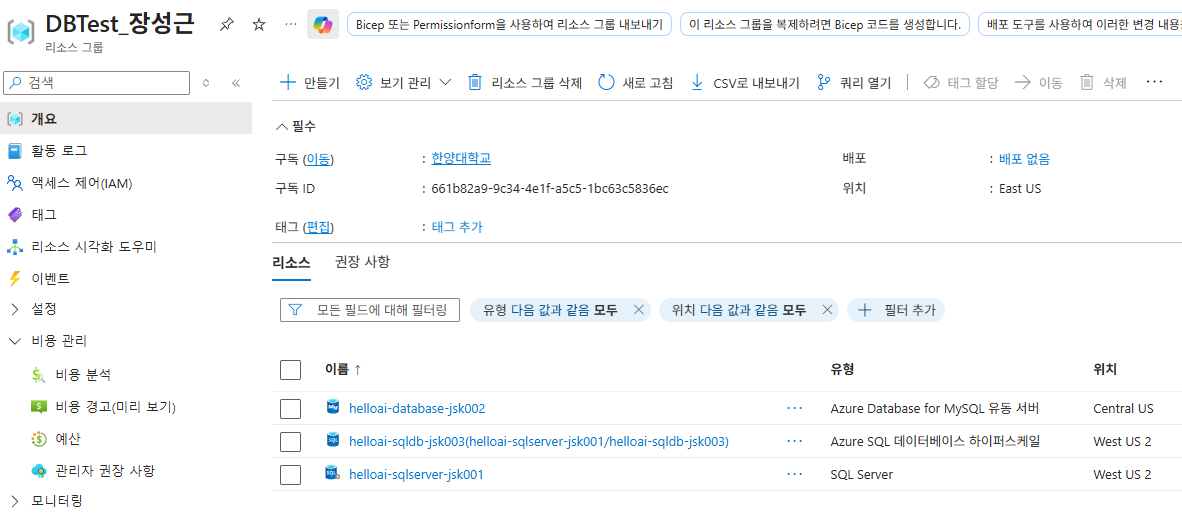
다음으로, 지난번 실습한 우분투 서버에서, sql 연결을 진행해보겠다.
우분투 서버에 ssh 원격 연결한 상태에서 시작한다

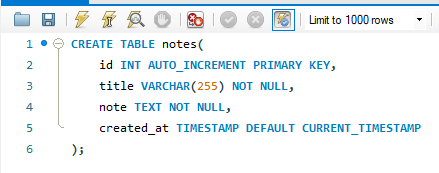

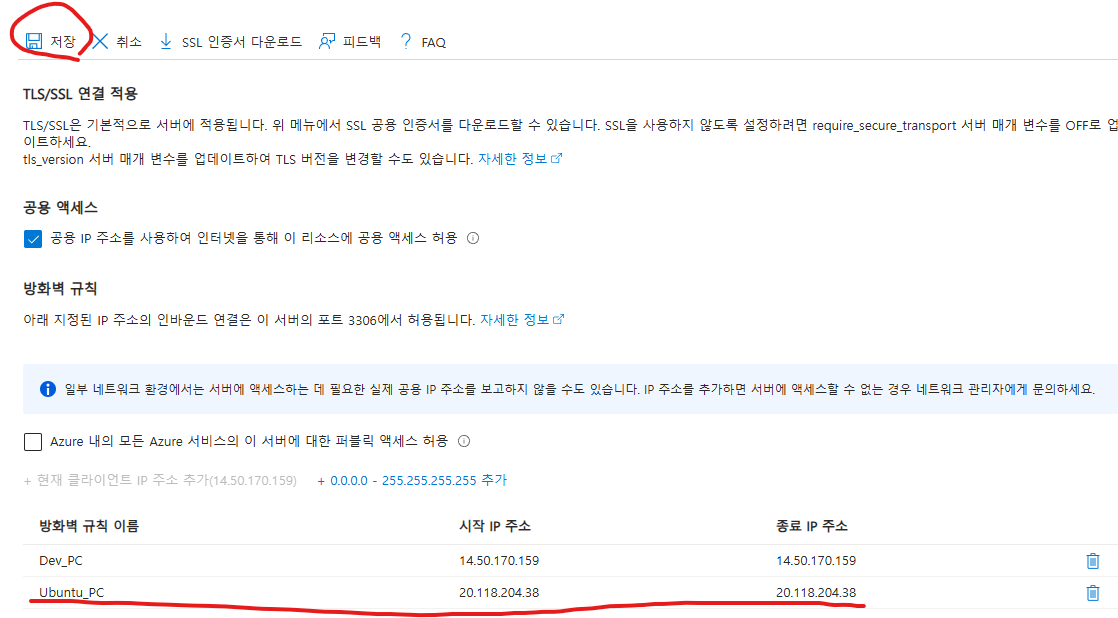




이전에 AOI 프로젝트를 진행하며 이미 경험해본 내용이지만
이번에는 클라우드를 활용해 보았다는 점에서 의미가 있는 실습이었다.
정리
- 관계형 DB의 핵심 객체는 Table, Entity, Index, View이며, 정규화와 관계(PK/FK)를 통해 데이터 무결성을 보장한다
- SQL은 DML(데이터 조작), DDL(구조 정의), DCL(권한 관리) 세 가지로 분류된다
- Azure SQL은 VM(IaaS), SQL Database(PaaS), Managed Instance(PaaS) 세 가지 형태로 제공되며, 관리 부담과 제어 수준에 따라 선택한다
- Managed Instance는 온프레미스 SQL Server와 거의 100% 호환되어 마이그레이션에 적합하다
- Python에서 MySQL 연결 시 MySQL Connector를 사용하며, 데이터 조작은 SQL을 그대로 쓴다
'개인공부' 카테고리의 다른 글
| [클라우드응용SW개발] 3. 클라우드 데이터 플랫폼(1) (0) | 2026.03.24 |
|---|---|
| [클라우드응용SW개발] 2. 리눅스 기반 웹 서버 구축하기 (0) | 2026.03.24 |
| [클라우드응용SW개발] 1. 클라우드 서비스 이해하기 (0) | 2026.03.23 |
| [MQTT / Python / IoT] AoI를 고려한 큐 버퍼 관리 알고리즘 개발 (0) | 2026.01.21 |
| [Linux / SSH / IoT] Ansible을 활용한 환경 구성 자동화 (0) | 2026.01.05 |